Etapas del proceso de desarrollo de software
Cualquier sistema de información va pasando por una serie de fases a lo largo de su vida. Su ciclo de vida comprende una serie de etapas entre las que se encuentran las siguientes:
- Análisis
- Diseño
- Implementación
- Pruebas
- Instalación o despliegue
- Uso y mantenimiento
Para cada una de las fases en que hemos descompuesto el ciclo de vida de un sistema de información se han propuesto multitud de prácticas útiles, entendiendo por prácticas aquellos conceptos, principios, métodos y herramientas que facilitan la consecución de los objetivos de cada etapa.
- Análisis:
Esta etapa corresponde al proceso mediante el cual se intenta descubrir qué es lo que realmente se necesita y se llega a una comprensión adecuada de los requerimientos del sistema (las características que el sistema debe poseer, y puede ser de diversas actividades que servirán como fundamento para la elaboración de las fases posteriores).
¿Por qué resulta esencial la etapa de análisis? Simplemente, porque si no sabemos con precisión qué es lo que se necesita, ningún proceso de desarrollo nos permitirá obtenerlo. El problema es que, de primeras, puede que ni nuestro cliente sepa de primeras qué es exactamente lo que necesita. Por tanto, deberemos ayudarle a averiguarlo con ayuda de distintas técnicas.
¿Por qué es tan importante averiguar exactamente cuáles son los requerimientos del sistema si el software es fácilmente maleable (aparentemente)? Porque el coste de construir correctamente un sistema de información a la primera es mucho menor que el coste de construir un sistema que habrá que modificar más adelante. Cuanto antes se detecte un error, mejor. Distintos estudios han demostrado que eliminar un error en las fases iniciales de un proyecto (en la etapa de análisis) resulta de 10 a 100 veces más económico que subsanarlo al final del proyecto. Conforme avanza el proyecto, el software se va describiendo con un mayor nivel de detalle, se concreta cada vez más y se convierte en algo cada vez más rígido.
¿Es posible determinar de antemano todos los requerimientos de un sistema de información? Desgraciadamente, no. De hecho, una de las dos causas más comunes de fracaso en proyectos de desarrollo de software es la inestabilidad de los requerimientos del sistema (la otra es una mala estimación del esfuerzo requerido por el proyecto). En el caso de una mala estimación, el problema se puede solucionar estableciendo objetivos más realistas. Sin embargo, en las etapas iniciales de un proyecto, no disponemos de la información necesaria para determinar exactamente el problema que pretendemos resolver. Por mucho tiempo que le dediquemos al análisis del problema (un fenómeno conocido como la parálisis del análisis).
La inestabilidad de los requerimientos de un sistema es inevitable. Se estima que un 25% de los requerimientos iniciales de un sistema cambian antes de que el sistema comience a utilizarse.
Muchas prácticas resultan efectivas para gestionar adecuadamente los requerimientos de un sistema y, en cierto modo, controlar su evolución. Un buen analista debería tener una formación adecuada en:
> Técnicas de licitación de requerimientos.
Este requiere previamente la identificación de las personas afectadas por el proyecto, sus stakeholders (literalmente, los que apuestan algo), lo que incluye desde el cliente que paga el proyecto hasta los usuarios finales de la aplicación, sin olvidarse de terceras personas y organizaciones relacionadas indirectamente con el sistema que se va a desarrollar (por ejemplo, empresas competidoras y organismos reguladores).
> Técnicas de licitación de requerimientos.
Este requiere previamente la identificación de las personas afectadas por el proyecto, sus stakeholders (literalmente, los que apuestan algo), lo que incluye desde el cliente que paga el proyecto hasta los usuarios finales de la aplicación, sin olvidarse de terceras personas y organizaciones relacionadas indirectamente con el sistema que se va a desarrollar (por ejemplo, empresas competidoras y organismos reguladores).
En la elicitación de requerimientos se recurre a distintas técnicas que favorezcan la comunicación entre el analista y el resto de personas involucradas, como puede ser la realización de entrevistas (en las que importa no sólo lo que se pregunta, sino cómo se pregunta), el diseño de cuestionarios (cuando no tenemos tiempo ni recursos para entrevistar personalmente a todo el mundo) o el desarrollo de prototipos (para recoger información que, de otra forma, no obtendríamos hasta las etapas finales del proyecto, cuando cualquier rectificación saldría mucho más cara). También se puede observar el funcionamiento normal del entorno en el que se instalará nuestro sistema o, incluso, participar activamente en él (por ejemplo, desempeñando temporalmente el trabajo de los usuarios de nuestro sistema). Por último, también podemos investigar por nuestra cuenta consultando documentos relacionados con el tema de nuestro proyecto o estudiando productos similares que ya existan en el mercado.
> Herramientas de modelado de sistemas.
Un modelo, básicamente, no es más que una simplificación de la realidad. El uso de modelos en la construcción de sistemas de información resulta esencial por los siguientes motivos:
- Los modelos ayudan a comunicar la estructura de un sistema complejo (y, por tanto, a comunicarnos con las demás personas involucradas en un proyecto).
- Los modelos sirven para especificar el comportamiento deseado del sistema
(como guía para las etapas posteriores del proyecto).
- Los modelos nos ayudan a comprender mejor lo que estamos diseñando (por ejemplo, para detectar inconsistencias y corregirlas).
- Los modelos nos permiten descubrir oportunidades de simplificación (ahorrarnos trabajo en el proyecto actual) y de reutilización (ahorrarnos trabajo en futuros proyectos).
En resumidas cuentas, los modelos, entre otras cosas, facilitan el análisis de los
requerimientos del sistema, así como su posterior diseño e implementación. Un modelo, en
definitiva, proporciona "los planos" de un sistema. El modelo ha de capturar "lo esencial"
desde determinado punto de vista. En función de para qué queramos el modelo, lo haremos
más o menos detallado, siempre de acuerdo a su relevancia y utilidad.
Un sistema de información es un sistema complejo, por lo que a (casi) nadie se le ocurriría
intentar describirlo utilizando un único modelo. De hecho, todo sistema puede describirse
desde distintos puntos de vista y nosotros utilizaremos distintos tipos de modelos dependiendo
del aspecto del sistema en que deseemos centrar nuestra atención:
- Existen modelos estructurales que nos ayudan a la hora de organizar un sistema
complejo. Por ejemplo, un diagrama entidad/relación nos indica cómo se estructuran los datos de un sistema de información, mientras que un diagrama de
flujo de datos nos da información acerca de cómo se descompone un sistema en
subsistemas y del flujo de datos que existe entre los distintos subsistemas.
- También existen modelos de comportamiento que nos permiten analizar y
modelar la dinámica de un sistema. Por ejemplo, un diagrama de estados
representa los distintos estados en que puede encontrarse un sistema y cómo se
puede pasar de un estado a otro, mientras que la descripción de un caso de uso nos
ayuda a comprender la secuencia de pasos involucrada en la consecución de un
objetivo concreto por parte de un usuario del sistema.
> Metodologías de análisis de requerimientos.
Las técnicas de los párrafos anteriores deben utilizarse acompañadas de una metodología adecuada. En este contexto, una metodología no es más que un conjunto de convenciones que han resultado útiles en la práctica y cuyo uso combinado se recomienda.
Las metodologías de análisis particulares, de las que hay muchas, usualmente están ligadas, o
bien al uso de determinadas herramientas (por lo que el vendedor de la herramienta se
convierte, muchas veces, en el único promotor de la metodología), o bien a empresas de
consultoría concretas (que ofrecen cursos de aprendizaje de la metodología que proponen).
En general, no obstante, la elección adecuada de las técnicas utilizadas dependerá de la
situación concreta en la que se encuentre nuestro proyecto. Por este motivo, lo más adecuado
es aprender cuantas más técnicas mejor y averiguar en qué situaciones resulta más efectiva
cada una de ellas.
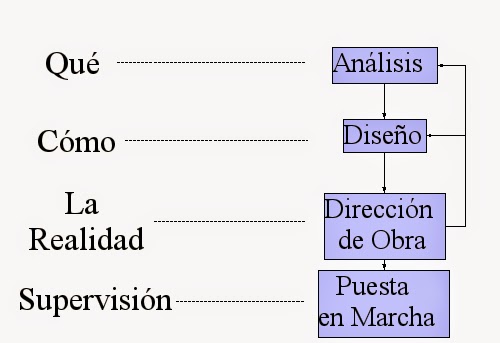
- Diseño
Mientras que los modelos utilizados en la etapa de análisis representan los requisitos del
usuario desde distintos puntos de vista (el qué), los modelos que se utilizan en la fase de
diseño representan las características del sistema que nos permitirán implementarlo de forma
efectiva (el cómo).
Un software bien diseñado debe exhibir determinadas características. Su diseño debería ser
modular en vez de monolítico. Sus módulos deberían ser cohesivos (encargarse de una tareaconcreta y sólo de una) y estar débilmente acoplados entre sí (para facilitar el mantenimiento
del sistema). Cada módulo debería ofrecer a los demás unos interfaces bien definidos (al estilo del diseño por contrato propuesto por Bertrand Meyer) y ocultar sus detalles de implementación (siguiendo el principio de ocultación de información de Parnas). Por último, debe ser posible relacionar las decisiones de diseño tomadas con los requerimientos del sistema que las ocasionaron (algo que se suele denominar "trazabilidad de los requerimientos").
En la fase de diseño se han de estudiar posibles alternativas de implementación para el sistema de información que hemos de construir y se ha de decidir la estructura general que tendrá el sistema (su diseño arquitectónico). El diseño de un sistema es complejo y el proceso de diseño ha de realizarse de forma iterativa. La solución inicial que propongamos probablemente no resulte la más adecuada para nuestro sistema de información, por lo que deberemos refinarla. Afortunadamente, tampoco es necesario que empecemos desde cero. Existen auténticos catálogos de patrones de diseño que nos pueden servir para aprender de los errores que otros han cometido sin que nosotros tengamos que repetirlos. Igual que en la etapa de análisis creábamos distintos modelos en función del aspecto del sistema en que centrábamos nuestra atención, el diseño de un sistema de información también presenta distintas facetas:
- Por un lado, es necesario abordar el diseño de la base de datos, un tema que trataremos detalladamente más adelante.
- Por otro lado, también hay que diseñar las aplicaciones que permitirán al usuario utilizar el sistema de información. Tendremos que diseñar la interfaz de usuario del sistema y los distintos componentes en que se descomponen las aplicaciones.
De esto último hablaremos en las dos secciones siguientes:
°Arquitecturas multicapa
La división de un sistema en distintas capas o niveles de abstracción es una de las técnicas
más comunes empleadas para construir sistemas complejos (esta división se puede apreciar en el hardware).
En realidad, el uso de capas es una forma más de la técnica de resolución de problemas
conocida con el nombre de "divide y vencerás", que se basa en descomponer un problema complejo en una serie de problemas más sencillos de forma que se pueda obtener la solución
al problema complejo a partir de las soluciones a los problemas más sencillos. Al dividir un
sistema en capas, cada capa puede tratarse de forma independiente (sin tener que conocer los
detalles de las demás).
Desde el punto de vista de la Ingeniería del Software, la división de un sistema en capas
facilita el diseño modular (cada capa encapsula un aspecto concreto del sistema) y permite la
construcción de sistemas débilmente acoplados (si minimizamos las dependencias entre
capas, resultará más fácil sustituir la implementación de una capa sin afectar al resto del
sistema). Además, el uso de capas también fomenta la reutilizació .
Como es lógico, la parte más difícil en la construcción de un sistema multicapa es decidir
cuántas capas utilizar y qué responsabilidades asignarle a cada capa.
En las arquiecturas cliente/servidor se suelen utilizar dos capas. En el caso de las
aplicaciones informáticas de gestión, esto se suele traducir en un servidor de bases de datos en
el que se almacenan los datos y una aplicación cliente que contiene la interfaz de usuario y la
lógica de la aplicación.
El problema con esta descomposición es que la lógica de la aplicación suele acabar mezclada
con los detalles de la interfaz de usuario, dificultando las tareas de mantenimiento a que todo
software se ve sometido y destruyendo casi por completo la portabilidad del sistema, que
queda ligado de por vida a la plataforma para la que se diseñó su interfaz en un primer
momento.
Mantener la misma arquitectura y pasar la lógica de la aplicación al servidor tampoco resulta
una solución demasiado acertada. Se puede implementar la lógica de la aplicación utilizando
procedimientos almacenados, pero éstos suelen tener que implementarse en lenguajes
estructurados no demasiado versátiles. Además, suelen ser lenguajes específicos para cada
tipo de base de datos, por lo que la portabilidad del sistema se ve gravemente afectada.
La solución, por tanto, pasa por crear nueva capa en la que se separe la lógica de la aplicación
de la interfaz de usuario y del mecanismo utilizado para el almacenamiento de datos. El
sistema resultante tiene tres capas:
- La capa de presentación, encargada de interactuar con el usuario de la aplicación mediante una interfaz de usuario
- La lógica de la aplicación, usualmente implementada utilizando un modelo orientado a objetos del dominio de la aplicación, es la responsable de realizar las tareas para
las cuales se diseña el sistema.
- La capa de acceso a los datos, encargada de gestionar el almacenamiento de los
datos, generalmente en un sistema gestor de bases de datos relacionales, y de la
comunicación del sistema con cualquier otro sistema que realice tareas auxiliares.
Cuando el usuario del sistema no es un usuario humano, se hace evidente la similitud entre las
capas de presentación y de acceso a los datos. Teniendo esto en cuenta, el sistema puede verse
como un núcleo (lógica de la aplicación) en torno al cual se crean una serie de interfaces con
entidades externas.
No obstante, aunque sólo fuese por las peculiaridades del diseño de interfaces de usuario,
resulta útil mantener la vista asimétrica del software como un sistema formado por tres capas.Además, suele ser recomendable diferenciar lo que se
suministra (presentación) de lo que se consume (acceso a los servicios suministrados por otros
sistemas).
°Notas acerca del diseño de las aplicaciones
Como en cualquier otra tarea de diseño, tenemos que llegar a un
compromiso adecuado entre distintos intereses. Por lo general, el diseño de la lógica una aplicación se suele ajustar a uno de los tres
siguientes patrones de diseño:
- Rutinas: La forma más simple de implementar cualquier sistema se basa en implementar procedimientos y funciones que acepten y validen las entradas recibidas de la capa de presentación, realicen los cálculos necesarios, utilicen los servicios de aquellos sistemas que hagan falta para completar la operación, almacenen los datos en las bases de datos y envíen una respuesta adecuada al
usuario. Básicamente, cada acción que el usuario pueda realizar se traducirá en un
procedimiento que realizará todo lo que sea necesario al más puro estilo del
diseño estructurado tradicional. Aunque este modelo sea simple y pueda resultar
adecuado a pequeña escala, la evolución de las aplicaciones diseñadas de esta
forma suele acabar siendo una pesadilla para las personas encargadas de su
mantenimiento.
- Módulos de datos: Ante la situación descrita en el párrafo anterior, lo usual es dividir el sistema utilizando los distintos conjuntos de datos con los que trabaja la aplicación para crear módulos más o menos independientes. De esta forma, se facilita la eliminación de lógica duplicada. De hecho, muchos de los entornos de desarrollo visual de aplicaciones permiten definir módulos de datos que encapsulen los conjuntos de datos con los que se trabaja y la lógica asociada a ellos. Las herramientas de Borland, Delphi y C++Builder, son un claro ejemplo, igual que el Developer de Oracle. Microsoft, en su arquitectura DNA [Distributed interNet Application], fomenta este estilo al emplear conjuntos de datos (resultado de ejecutar consultas SQL) sobre los cuales operan directamente las distintas capas de una aplicación multicapa. En el caso de la plataforma .NET, la clase DataSet proporciona la base sobre la que se montaría todo el diseño de una aplicación (algo que obviamente facilita el Visual Studio .NET).
- Modelo del dominio: Una tercera opción, la ideal para cualquier purista de la orientación a objetos, es crear un modelo orientado a objetos del dominio de la aplicación. En vez de que una rutina se encargue de todo lo que haya que hacer para completar una acción, cada objeto es responsable de realizar las tareas que le atañen directamente.
- Implementación
Para la fase de implementación hemos de seleccionar las herramientas adecuadas, un entorno de desarrollo que facilite nuestro trabajo y un lenguaje de programación apropiado para el tipo de sistema que vayamos a construir. La elección de estas herramientas dependerá en gran parte de las decisiones de diseño que hayamos tomado hasta el momento y del entorno en el que nuestro sistema deberá funcionar.
A la hora de programar, deberemos procurar que nuestro código no resulte indescifrable. Para que nuestro código sea legible, hemos de evitar estructuras de control no estructuradas, elegir cuidadosamente los identificadores de nuestras variables, seleccionar algoritmos y estructuras de datos adecuadas para nuestro problema, mantener la lógica de nuestra aplicación lo más sencilla posible, comentar adecuadamente el texto de nuestros programas y, por último, facilitar la interpretación visual de nuestro código mediante el uso de sangrías y líneas en blanco que separen distintos bloques de código.
Además de las tareas de programación asociadas a los distintos componentes de nuestro sistema, en la fase de implementación también hemos de encargarnos de la adquisición de todos los recursos necesarios para que el sistema funcione. Usualmente, también desarrollaremos algunos casos de prueba que nos permitan ir comprobando el funcionamiento de nuestro sistema conforme vamos construyéndolo.
- Pruebas
Esta etapa tiene como objetivo detectar los errores que se hayan
podido cometer en las etapas anteriores del proyecto (y, eventualmente, corregirlos). Además, es hacerlo antes de que el usuario final del sistema los tenga que sufrir. De hecho,
una prueba es un éxito cuando se detecta un error (y no al revés)
La búsqueda de errores que se realiza en la etapa de pruebas puede adaptar distintas formas,
en función del contexto y de la fase del proyecto en la que nos encontremos:
- Las pruebas de unidad sirven para comprobar el correcto funcionamiento de un componente concreto de nuestro sistema. Es este tipo de pruebas, el "probador" debe buscar situaciones límite que expongan las limitaciones de la implementación del componente, ya sea tratando éste como una caja negra ("pruebas de caja negra") o fijándonos en su estructura interna ("pruebas de caja blanca").
- Las pruebas de integración son las que se realizan cuando vamos juntando los componentes que conforman nuestro sistema y sirven para detectar errores en sus interfaces.
- Una vez "finalizado" el sistema, se realizan pruebas alfa en el seno de la
organización encargada del desarrollo del sistema. Estas pruebas, realizadas desde
el punto de vista de un usuario final, pueden ayudar a pulir aspectos de la interfaz
de usuario del sistema
- Cuando el sistema no es un producto a medida, sino que se venderá como un producto en el mercado, también se suelen realizar pruebas beta. Estas pruebas las hacen usuarios finales del sistema ajenos al equipo de desarrollo y pueden resultar vitales para que un producto tenga éxito en el mercado.
- En sistemas a medida, se suele realizar un test de aceptación que, si se supera con éxito, marcará oficialmente el final del proceso de desarrollo y el comienzo de la etapa de mantenimiento.
- Por último, a lo largo de todo el ciclo de vida del software, se suelen hacer revisiones de todos los productos generados a lo largo del proyecto, desde el documento de especificación de requerimientos hasta el código de los distintos módulos de una aplicación. Estas revisiones, de carácter más o menos formal, ayuden a verificar la corrección del producto revisado y también a validarlo (comprobar que se ajusta a los requerimientos reales del sistema).
- Instalación / Despliegue
De cara a su instalación, hemos de planificar el entorno en el que el sistema debe funcionar,
tanto hardware como software: equipos necesarios y su configuración física, redes de
interconexión entre los equipos y de acceso a sistemas externos, sistemas operativos
(actualizados para evitar problemas de seguridad), bibliotecas y componentes suministrados
por terceras partes, etcétera.
Para asegurar el correcto funcionamiento del sistema, resulta esencial que tengamos en cuenta
las dependencias que pueden existir entre los distintos componentes del sistema y sus
versiones. Una aplicación puede que sólo funcione con una versión concreta de una biblioteca
auxiliar. Un disco duro puede que sólo rinda al nivel deseado si instalamos un controlador
concreto. Componentes que por separado funcionarían correctamente, combinados causan
problemas, por lo que deberemos utilizar sólo combinaciones conocidas que no presenten
problemas de compatibilidad.
Si nuestro sistema reemplaza a un sistema anterior o se despliega paulatinamente en distintas
fases, también hemos de planificar cuidadosamente la transición del sistema antiguo al nuevo
de forma que sus usuarios no sufran una disrupción en el funcionamiento del sistema. En
ocasiones, el sistema se instala físicamente en un entorno duplicado y la transición se hace de
forma instantánea una vez que la nueva configuración funciona correctamente.
- Uso y mantenimiento
La etapa de mantenimiento consume típicamente del 40 al 80 por ciento de los recursos de
una empresa de desarrollo de software. De hecho, con un 60% de media, es probablemente la
etapa más importante del ciclo de vida del software. Dada la naturaleza del software, que ni se
rompe ni se desgasta con el uso, su mantenimiento incluye tres facetas diferentes:
- Eliminar los defectos que se detecten durante su vida útil (mantenimiento correctivo), lo primero que a uno se le viene a la cabeza cuando piensa en el mantenimiento de cualquier cosa.
- Adaptarlo a nuevas necesidades (mantenimiento adaptativo), cuando el sistema ha de funcionar sobre una nueva versión del sistema operativo o en un entorno hardware diferente, por ejemplo.
- Añadirle nueva funcionalidad (mantenimiento perfectivo), cuando se proponen características deseables que supondrían una mejora del sistema ya existente.
De las distintas facetas del mantenimiento, la eliminación de defectos sólo supone el 17% del coste de mantenimiento de un sistema, mientras que el diseño e implementación de mejoras es responsable del 60% del coste de mantenimiento. Es decir, más de un tercio del coste total del software se emplea en añadirle características a software ya existente (el 60% del 60%). La corrección de errores supone, en contraste, "sólo" en torno al 10% del coste total del software. Aún menos cuanto mejores sean las técnicas usadas en su desarrollo.
Se ha observado que, cuanto mejor sea el software, más tendremos que invertir en su mantenimiento, aun cuando se emplee menos esfuerzo en corregir defectos. Este hecho, que puede parecer paradójico, se debe, simplemente, a que nuestro sistema se usará más (a veces, de formas que no habíamos previsto). Por tanto, nos llegarán más propuestas de modificación y mejora que si el sistema hubiese quedado aparcado, cogiendo polvo, en algún rincón.
Si examinamos las tareas que se llevan a cabo durante la etapa de mantenimiento, nos encontramos que en el mantenimiento se repiten todas las etapas que ya hemos visto del ciclo de vida de un sistema de información. Al tratar principalmente de cómo añadirle nueva funcionalidad a un sistema ya existente, el mantenimiento repite "en miniatura" el ciclo de vida completo de un sistema de información. Es más, a las tareas normales de desarrollo hemos de añadirle una nueva, comprender el sistema que ya existe, por lo que se podría decir que el mantenimiento de un sistema es más difícil que su desarrollo
No hay comentarios.:
Publicar un comentario