 |
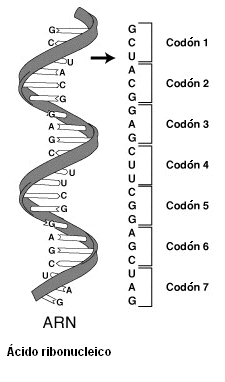
Serie de codones en un segmento de ADN.
Cada codón se compone de tres nucleótidos
que codifican un aminoácido específico.
|
El código genético (contenido del ADN, que ordena el desarrollo, crecimiento y el mantenimiento de los seres vivos) es el conjunto de reglas que define la traducción de una secuencia de nucleótidos en el ARN a una secuencia de aminoácidos en una proteína, en todos los seres vivos. El código define la relación entre secuencias de tres nucleótidos, llamadas codones, y aminoácidos. De ese modo, cada codón se corresponde con un aminoácido específico.
La secuencia del material genético se compone de cuatro bases nitrogenadas distintas, que tienen una función equivalente a letras en el código genético:
------------------------------------------
- ADN ARN
------------------------------------------- ADN ARN
adenina(A) uracilo (U)
timina (T) adenina (A)
guanina (G) citosina (C)
citosina (C) guanina (G)
------------------------------------------
ADN ==========> ARN ==========> Proteína
Transcripción Traducción
Ejemplo:
ACA GAC AGA TAC AAT se transcribe a ACA GAC AGA UAC AAU
La información genética es traducida por la maquinaria celular para producir las proteínas usando el código genético, el cual determina la secuencia de aminoácidos codificada en el ADN y luego en el ARN. Durante la traducción la maquinaria celular utiliza la molécula de ARN como molde para sintetizar una cadena de aminoácidos codificada en la misma. Para ello interpreta el código leyendo de a 3 nucleótidos, esta unidad se denomina codón, cada codón codifica para un aminoácido.
Ejemplo:
Si dividimos la secuencia de ARN anterior de a 3 nucleótidos obtenemos los
siguientes 5 codones, los cuales se traducen en 5 aminoácidos:
ACA-GAC-AGA-UAC-AAU se traduce a T D R Y N
Nótese que la información contenida en la molécula de ADN y de ARN es la misma,
por lo cual se puede obtener la secuencia proteica codificada en una molécula de
ADN a partir de su secuencia.
Debido a esto, el número de codones posibles es 64, de los cuales 61 codifican aminoácidos (siendo además uno de ellos el codón de inicio, AUG) y los tres restantes son sitios de parada (UAA, llamado ocre; UAG, llamado ámbar; UGA, llamado ópalo). La secuencia de codones determina la secuencia de aminoácidos en una proteína en concreto, que tendrá una estructura y una función específicas.
Debido a esto, el número de codones posibles es 64, de los cuales 61 codifican aminoácidos (siendo además uno de ellos el codón de inicio, AUG) y los tres restantes son sitios de parada (UAA, llamado ocre; UAG, llamado ámbar; UGA, llamado ópalo). La secuencia de codones determina la secuencia de aminoácidos en una proteína en concreto, que tendrá una estructura y una función específicas.

Una vez que Crick (1958) propuso la Hipótesis de la Secuencia ("existe una relación entre la ordenación lineal de nucleótidos en el ADN y la ordenación lineal de aminoácidos en los polipéptidos"), la comunidad científica la admitió y se plantearon dos preguntas:
"¿Existe algún código o clave que permite pasar de la secuencia de nucleótidos en el ADN a la secuencia de aminoácidos en las proteínas?"
"¿Cómo se convierte la información contenida en la secuencia de ADN en una estructura química de proteína?"
La primera pregunta conlleva el estudio del desciframiento del código genético y el estudio de sus características.
La segunda pregunta consiste en el estudio de los procesos genéticos de la síntesis de proteínas: la transcripción y la traducción.
 |
| Sydney Brenner -Fancis Crick |
Caracteristicas:
Las características del código genético fueron establecidas experimentalmente por Fancis Crick, Sydney Brenner y colaboradores en 1961.
Las principales características del código genético son las siguientes:
> El código está organizado en tripletes o codones: cada tres nucleótidos (triplete) determinan un aminoácido.
Si cada nucleótido determinara un aminoácido, solamente podríamos codificar cuatro aminoácidos diferentes ya que en el ADN solamente hay cuatro nucleótidos distintos. Cifra muy inferior a los 20 aminoácidos distintos que existen.
Si cada dos nucleótidos codificarán un aminoácido, el número total de dinucleótidos distintos que podríamos conseguir con los cuatro nucleótidos diferentes (A, G, T y C) serían variaciones con repetición de cuatro elementos tomados de dos en dos VR4,2 = 42 = 16. Por tanto, tendríamos solamente 16 dinucleótidos diferentes, cifra inferior al número de aminoácidos distintos que existen (20).
Si cada grupo de tres nucleótidos determina un aminoácido. Teniendo en cuenta que existen cuatro nucleótidos diferentes (A, G, T y C), el número de grupos de tres nucleótidos distintos que se pueden obtener son variaciones con repetición de cuatro elementos (los cuatro nucleótidos) tomados de tres en tres: VR4,3 = 43 = 64. Por consiguiente, existe un total de 64 tripletes diferentes, cifra más que suficiente para codificar los 20 aminoácidos distintos.
Si cada nucleótido determinara un aminoácido, solamente podríamos codificar cuatro aminoácidos diferentes ya que en el ADN solamente hay cuatro nucleótidos distintos. Cifra muy inferior a los 20 aminoácidos distintos que existen.
Si cada dos nucleótidos codificarán un aminoácido, el número total de dinucleótidos distintos que podríamos conseguir con los cuatro nucleótidos diferentes (A, G, T y C) serían variaciones con repetición de cuatro elementos tomados de dos en dos VR4,2 = 42 = 16. Por tanto, tendríamos solamente 16 dinucleótidos diferentes, cifra inferior al número de aminoácidos distintos que existen (20).
Si cada grupo de tres nucleótidos determina un aminoácido. Teniendo en cuenta que existen cuatro nucleótidos diferentes (A, G, T y C), el número de grupos de tres nucleótidos distintos que se pueden obtener son variaciones con repetición de cuatro elementos (los cuatro nucleótidos) tomados de tres en tres: VR4,3 = 43 = 64. Por consiguiente, existe un total de 64 tripletes diferentes, cifra más que suficiente para codificar los 20 aminoácidos distintos.
> El código genético es degenerado: existen más tripletes o codones que aminoácidos, de forma que un determinado aminoácido puede estar codificado por más de un triplete.
Como hemos dicho anteriormente existen 64 tripletes distintos y 20 aminoácidos diferentes, de manera que un aminoácido puede venir codificado por más de un codón. Este tipo de código se denomina degenerado. Wittmann (1962) induciendo sustituciones de bases por desaminación con nitritos, realizó sustituciones de C por U y de A por G en el ARN del virus del mosaico del tabaco (TMV), demostrando que la serina y la isoleucina estaban determinadas por más de un triplete.
Las moléculas encargadas de transportar los aminoácidos hasta el ribosoma y de reconocer los codones del ARN mensajero durante el proceso de traducción son los ARN transferentes (ARN-t). Los ARN-t tienen una estructura en forma de hoja de trébol con varios sitios funcionales:
- Extremo 3': lugar de unión al aminoácido (contiene siempre la secuencia ACC).
- Lazo dihidrouracilo (DHU): lugar de unión a la aminoacil ARN-t sintetasa o enzimas encargadas de unir una aminoácido a su correspondiente ARN-t.
- Lazo de T ψ C: lugar de enlace al ribosoma.
- Lazo del anticodón: lugar de reconocimiento de los codones del mensajero.
Normalmente el ARN-t adopta una estructura de hoja de trébol plegada en forma de L o forma de boomerang.
Los ARN-t suelen presentar bases nitrogenadas poco frecuentes como son la pseudouridina (ψ), metilguanosina (mG), dimetilguanosina (m2G), metilinosina (mI) y dihidrouridina (DHU, UH2).
El que realiza el reconocimiento del codón correspondiente del ARN-m es el anticodón del ARN-t y no el aminoácido. Mediante un experimento se demostró que era posible transformar el cisteinil-ARN-t mediante tratamiento con hidruro de níquel en alanil-ARN-t. Este tratamiento convierte la cisteína en alanina. De esta manera se consiguió un ARN-t específico de cisteina que en lugar de llevar unida cisteina llevaba unida alanina. Cuando se empleo este ARN-t híbrido para sintetizar proteínas se pudo comprobar que en el lugar en el que debía aparecer cisteina en la secuencia del polipéptido aparecía alanina. Por tanto, el que llevaba a cabo el reconocimiento del codón del ARN-m era el anticodón del ARN-t y no el aminoácido.
La degeneración del código se explica teniendo en cuenta dos motivos:
- Algunos aminoácidos pueden ser transportados por distintas especies moleculares (tipos) de ARN transferentes (ARN-t) que contienen distintos anticodones.
- Algunas especies moleculares de ARN-t pueden incorporar su aminoácido específico en respuesta a varios codones, de manera que poseen un anticodón que es capaz de emparejarse con varios codones diferentes. Este emparejamiento permisivo se denominaFlexibilidad de la 3ª base del anticodón o tambaleo.
> El código genético es no solapado o sin superposiciones: un nucleótido solamente pertenece a un único triplete.
Un nucleótido solamente forma parte de un triplete y, por consiguiente, no forma parte de varios tripletes, lo que indica que el código genético no presenta superposiciones. Por tanto, el código es no solapado.
Wittmann (1962) induciendo mutaciones con ácido nitroso en el ARN del virus del mosaico del tabaco (TMV) pudo demostrar que las mutaciones habitualmente producían un cambio en un solo aminoácido.
El ácido nitroso produce desaminaciones que provocan sustituciones de bases, si el código fuera solapado y un nucleótido formará parte de dos o tres tripletes, la sustitución de un nucleótido daría lugar a dos o tres aminoácidos alterados en la proteína de la cápside del TMV.
Otra forma de comprobar que el código es sin superposición es que no hay ninguna restricción en la secuencia de aminoácidos de las proteínas, de manera, que un determinado aminoácido puede ir precedido o seguido de cualquiera de los 20 aminoácidos que existen. Si dos codones sucesivos compartieran dos nucleótidos, cualquier triplete solamente podría ir precedido o seguido por cuatro codones determinados. Por consiguiente, si el código fuera superpuesto, un aminoácido determinado solamente podría ir precedido o seguido de otros cuatro aminoácidos como mucho.
> La lectura es "sin comas": el cuadro de lectura de los tripletes se realiza de forma continua "sin comas" o sin que existan espacios en blanco.
Teniendo en cuenta que la lectura se hace de tres en tres bases, a partir de un punto de inicio la lectura se lleva a cabo sin interrupciones o espacios vacíos, es decir, la lectura es seguida "sin comas". De manera, que si añadimos un nucleótido (adición) a la secuencia, a partir de ese punto se altera el cuadro de lectura y se modifican todos los aminoácidos. Lo mismo sucede si se pierde (deleción) un nucleótido de la secuencia. A partir del nucleótido delecionado se altera el cuadro de lectura y cambian todos los aminoácidos. Si la adición o la deleción es de tres nucleótidos o múltiplo de tres, se añade un aminoácido o más de uno a la secuencia que sigue siendo la misma a partir del la última adición o deleción. Una adición y una deleción sucesivas vuelven a restaurar el cuadro de lectura.
En la siguiente tabla se da un ejemplo con una frase que contiene solamente palabras de tres letras. A partir de la adición de una letra cambia la pauta de lectura y el significado de la frase, lo mismo sucede cuando se pierde una letra. Una adición y una deleción sucesivas recuperan el significado de la frase. Una adición de tres letras añade una palabra pero después se recupera la pauta de lectura y el sentido de la frase.
| Secuencia normal: ejemplo con una frase | |||||
| UNO | MAS | UNO | SON | DOS | |
| Adición de una A después de la primera N: cambia el cuadro de lectura | |||||
| UNA | OMA | SUN | OSO | NDO | S |
| Deleción (pérdida) de la primera O: cambia el cuadro de lectura | |||||
| UNM | ASU | NOS | OND | OS | |
| Adición de A y deleción de A: se recupera el cuadro de lectura | |||||
| UNA | OMS | UNO | SON | DOS | |
| Adición de tres letras (AAA) | |||||
| UNO | AAA | MAS | UNO | SON | DOS |
El desciframiento del código genético se ha realizado fundamentalmente en la bacteria E. coli, por tanto, cabe preguntarse si el código genético de esta bacteria es igual que el de otros organismos tanto procarióticos como eucarióticos. Los experimentos realizados hasta la fecha indican que el código genético nuclear es universal, de manera que un determinado triplete o codón lleva información para el mismo aminoácido en diferentes especies. Hoy día existen muchos experimentos que demuestran la universalidad del código nuclear, algunos de estos experimentos son:
- Utilización de ARN mensajeros en diferentes sistemas acelulares. Por ejemplo ARN mensajero y ribosomas de reticulocitos de conejo con ARN transferentes de E. coli. En este sistema se sintetiza un polipéptido igual o muy semejante a la hemoglobina de conejo.
- Las técnicas de ingeniería genética que permiten introducir ADN de un organismo en otro de manera que el organismo receptor sintetiza las proteínas del organismo donante del ADN. Por ejemplo, la síntesis de proteínas humanas en la bacteria E. coli.
El código genético nos indica que aminoácido corresponde a cada triplete o codón del ARN mensajero.
- El triplete de iniciación suele ser AUG que codifica para Formil-metionina. También pueden actuar como tripletes de iniciación GUG (Val) y UGG (Leu) aunque con menor eficacia.
- Existen tres tripletes sin sentido o codones de terminación (FIN) que no codifican para ningún aminoácido: UAA (ocre), UAG (ambar) y UGA (ópalo).
- La mayoría de los aminoácidos están determinados por más de un triplete, excepto la metionina (AUG) y el triptófano (UGG) que son los únicos que poseen un solo triplete.
- Cuando un aminoácido está codificado por varios tripletes suele variar la tercera base, por ejemplo, la glicina es GGX, la alanina es GCX, la valina es GUX, la treonina es ACX. Sin embargo, hay varias excepciones en las que también puede variar la primera base, por ejemplo, la arginina es AGPu y CGX, la leucina es CUX y UUPu y la serina es UCX y AGPi.
El código genético mitocondrial es la única excepción a la universalidad del código, de manera que en algunos organismos los aminoácidos determinados por el mismo triplete o codón son diferentes en el núcleo y en la mitocondria.
Excepciones a la Universalidad del Código
| Organismo | Codón | Significado en Código Nuclear | Significado en Código Mitocondrial |
| Todos | UGA | FIN | Trp |
| Levadura | CUX | Leu | Thr |
| Drosophila | AGA | Arg | Ser |
| Humano, bovino | AGA, AGC | Arg | FIN |
| Humano, bovino | AUA | Ile | Met (iniciación) |
| Ratón | AUU, AUC, AUA | Ile | Met (iniciación) |
[Mas Información]
- (PDF) DNA, RNA, & El código genético
- (Video) Transcripcion y traduccion
[FUENTE]
- http://es.wikipedia.org/wiki/C%C3%B3digo_gen%C3%A9tico
- http://www.maristasgranada.net/webcole/documentos/Ciencias/Bach-2%BA/Biologia/4_Bases-Herencia/Genetica-Molecular/Codigo-Genetico.pdf
- http://difusion.df.uba.ar/ConectarIgualdad/Tutorial%20CodigoGenetico.pdf
- http://pendientedemigracion.ucm.es/info/genetica/grupod/Codigo/Codigo%20genetico.htm#universalidad
[FUENTE]
- http://es.wikipedia.org/wiki/C%C3%B3digo_gen%C3%A9tico
- http://www.maristasgranada.net/webcole/documentos/Ciencias/Bach-2%BA/Biologia/4_Bases-Herencia/Genetica-Molecular/Codigo-Genetico.pdf
- http://difusion.df.uba.ar/ConectarIgualdad/Tutorial%20CodigoGenetico.pdf
- http://pendientedemigracion.ucm.es/info/genetica/grupod/Codigo/Codigo%20genetico.htm#universalidad
No hay comentarios.:
Publicar un comentario